Возможности различных типов данных, литералов в Java — введение в Java 011 #
В четвёртом уроке мы затронули преобразования одних типов данных в другие. Давайте для начала посмотрим, что именно мы тогда учили.
Явные и неявные преобразования #
Значения, передаваемые переменным, можно привести в тот тип данных, которые переменная может принять. Вручную или автоматически, или явно и неявно.
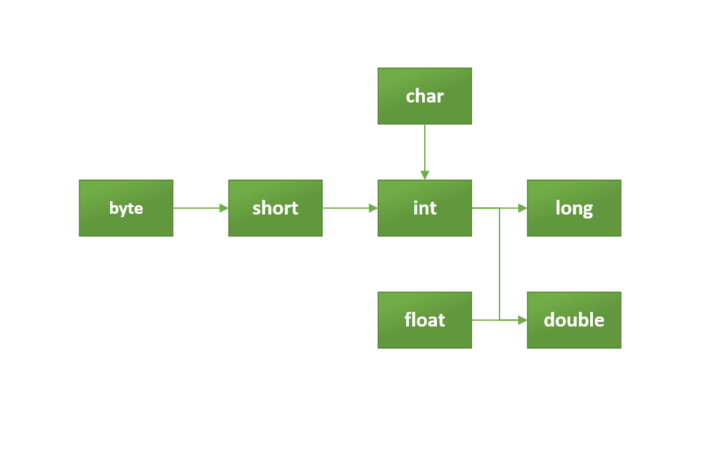
преобразование типов данных
Расширение типа (widening Casting), которое можно проследить на схеме с помощью стрелок, происходит автоматически. Это преобразование меньшего типа данных в типа большего размера: byte -> short -> char -> int -> long -> float -> double.
Сужение типа (narrowing Casting) — преобразование типа данных большего размера в тип данных меньшего размера — делается вручную: double -> float -> long -> int -> char -> short -> byte
String to int and double #
Помимо уже надеюсь привычного преобразования переменных и литералов из int в double И обратно мы можем большее.
String number = "10";
int result = Integer.parseInt(number);
System.out.println(result);
Parse #
The software parses and filters the incoming data.
Программное обеспечение разбирает и фильтрует поступающие данные.
int result = Integer.parseInt("709");
Java разбирает на составные части наш строковый литерал и если в нём содержится целочисленное значение, то успешно записывает его в переменную с типом данных int.
String.valueOf(3.14) #
Если у нас будет в строковом литерале десятичная дробь, то мы тоже можем “вытянуть” её.
double pi = 3.14;
String myPi = String.valueOf(pi);
Магия строки: String to char #
charAt - Что это за символ? #
Мы можем взять из стрингастрокового литерала любой символ и записать его в переменную с типом данных char.
String name = "Андрей";
char myChar = name.charAt(2);
Мы можем узнать числовое значение символьного литерала с помощью хитрости:
System.out.println(0 + myChar);
И это нам должно напомнить, что любой чар-литерал легко преобразовывается в инт-литерал. Давайте посмотрим всё сначала и вместе:
String name = "Андрей";
char myChar = name.charAt(2);
System.out.println(0 + myChar);
int myInt = myChar;
System.out.println(myInt);
substring #
Чар-литерал является частью строки. Точно так же мы можем даже “вырезать” любой символ из строкового литерала.
String name = "Андрей";
String myLittleString = name.substring(0, 1);
Но (пока) он так и останется строковым литералом, просто содержащим в себе один символ. Конечно же существуют ещё несколько возможностей разложить весь стринг на составные части, перебрать их и взять нужную часть. Но давайте пока разберёмся с charAt.
char myChar = "Андрей".charAt(2); // так тоже теоретически можно писать
Документация и доступные методы #
Я взял первых семь методов из официальной документации:
| Modifier and Type | Метод | Пояснение |
|---|---|---|
| char | charAt(int index) | Returns the char value at the specified index. |
| int | codePointAt(int index) | Returns the character (Unicode code point) at the specified index. |
| int | codePointBefore(int index) | Returns the character (Unicode code point) before the specified index. |
| int | codePointCount(int beginIndex, int endIndex) | Returns the number of Unicode code points in the specified text range of this String. |
| int | compareTo(String anotherString) | Compares two strings lexicographically. |
| int | compareToIgnoreCase(String str) | Compares two strings lexicographically, ignoring case differences. |
| String | concat(String str) | Concatenates the specified string to the end of this string. |
Ещё раз и “по-русски” #
| Метод | Перевод |
|---|---|
| charAt(int index) | Возвращает значение символа по указанному индексу. |
| codePointAt(int index) | Возвращает символ (Unicode code point) в указанном индексе. |
| codePointBefore(int index) | Возвращает символ (точка Юникода) перед указанным индексом. |
| codePointCount(int beginIndex, int endIndex) | Возвращает количество символов Юникода в указанном текстовом диапазоне данной строки. |
| compareTo(String anotherString) | Сравнивает две строки лексикографически. |
| compareToIgnoreCase(String str) | Сравнивает две строки лексикографически, игнорируя case написания |
| concat(String str) | Конкатенирует эту строку на конец другой строки. |
Лично мне перевод мало что сказал. Давайте посмотрим на примерах, что мы можем сделать.
charAt мы уже разобрали выше в этой же статье.
codePointAt(int index) - пример использования #
String testStr = "Группа студентов";
int result = testStr.codePointAt(1);
System.out.println("Результат проверки метода codePointAt = " + result);
На экране мы увидим:
Результат проверки метода codePointAt = 1088
codePointBefore(int index) - пример использования #
String str = "I love Java";
System.out.println("String = " + str);
int result = str.codePointBefore(1);
System.out.println("Character(unicode point) = " + result);
На экране мы увидим:
String = I love Java
Character(unicode point) = 73
codePointCount(int beginIndex, int endIndex) - пример использования #
System.out.println();
String str = "Мы учимся в школе Telran";
System.out.println("Оригинальная строка : " + str);
// codepoint from index 1 to index 10
int ctc = str.codePointCount(3, 10);
// prints character from index 1 to index 10
System.out.println("Считаем символы = " + ctc);
На экране мы увидим:
Оригинальная строка : Мы учимся в школе Telran
Считаем символы = 7
compareTo(String anotherString) - пример использования #
Значение 0, если аргумент является строкой, лексикографически равной этой строке; значение меньше 0, если аргумент является строкой, лексикографически большей, чем эта строка; и значение больше 0, если аргумент является строкой, лексикографически меньшей, чем эта строка.
Лексикографический порядок — отношение линейного порядка на множестве слов над некоторым упорядоченным алфавитом Sigma. Своё название лексикографический порядок получил по аналогии с сортировкой по алфавиту в словаре.
String str1 = "Строка для теста";
String str2 = "Строка для теста";
String str3 = "Другая строка для теста";
int result = str1.compareTo( str2 );
System.out.println(result);
result = str2.compareTo( str3 );
System.out.println(result);
result = str3.compareTo( str1 );
System.out.println(result);
Результат проверки compareTo(String anotherString):
0
13
-13
compareToIgnoreCase(String str) - пример использования #
String str1 = "Строка для теста";
String str2 = "сТрОкА дЛя тЕсТа";
String str3 = "Другая строка для теста";
int result = str1.compareToIgnoreCase(str2);
System.out.println(result);
result = str2.compareToIgnoreCase(str3);
System.out.println(result);
result = str3.compareToIgnoreCase(str1);
System.out.println(result);
Результат проверки compareToIgnoreCase(String str):
0
13
-13
concat(String str) - пример использования #
String str = "Привет";
str = str.concat(" Мир");
System.out.println(str);
Результат проверки concat(String str):
Привет Мир
К каждому типу данных существует множество стандартных методов. Важно уметь читать документацию и пользоваться поисковиками.
Домашнее задание #
Разобраться с методами:
- contains(CharSequence s)
- endsWith(String suffix)
- equals(Object anObject)
- equalsIgnoreCase(String anotherString)
- isEmpty()
- length()
- replace(char oldChar, char newChar)
- startsWith(String prefix)
- startsWith(String prefix, int toffset)
- substring(int beginIndex)
- toLowerCase()
- toUpperCase()
- trim()
Дополнительные ссылки #
- Oфициальная документация к String